- 이미지 생성
- qemu-img create -f qcow2 win2.qcow2 2G
- 이미지 할당
- dd if=/dev/zero of=/var/lib/libvirt/images/win2.qcow2 bs=1M count=2048
- 이미지 붙이기
- virsh attach-disk windows10 /var/lib/libvirt/images/win2.qcow2 vdb –cache none
Contact
PHP Generate UUID
function gen_uuid() {
return sprintf( '%04x%04x-%04x-%04x-%04x-%04x%04x%04x',
// 32 bits for "time_low"
mt_rand( 0, 0xffff ), mt_rand( 0, 0xffff ),
// 16 bits for "time_mid"
mt_rand( 0, 0xffff ),
// 16 bits for "time_hi_and_version",
// four most significant bits holds version number 4
mt_rand( 0, 0x0fff ) | 0x4000,
// 16 bits, 8 bits for "clk_seq_hi_res",
// 8 bits for "clk_seq_low",
// two most significant bits holds zero and one for variant DCE1.1
mt_rand( 0, 0x3fff ) | 0x8000,
// 48 bits for "node"
mt_rand( 0, 0xffff ), mt_rand( 0, 0xffff ), mt_rand( 0, 0xffff )
);
}중소기업청년전세대출

안녕하세요 오리입니다
오늘은 제가 중소기업취업청년전세자금대출(중소기업취업청년 전월세보증금대출)을
저는 부동산 전문가가 아니니 잘못된 정보가 있을 수 있습니다.
발견하신다면 너그럽게 알려주시면 수정하겠습니다.
(중소기업취업청년 전월세보증금대출)
·
자..잠깐!
금리 1.2%가 얼마나 말이 안되는 금리인가?
중소기업취업청년 전월세보증금대출을 통해
1억 전부 대출해도 1년 이자 120만원 > 120만원 나누기 12개월 > 1달 월세(이자) 10만원
① 회사가 조건에 부합하는 회사인지
(소속기업 규모확인)

중소기업취업청년 전월세보증금대출 공식 홈페이지 조회 링크입니다.
http://nhuf.molit.go.kr/FP/FP05/FP0502/FP05020604.jsp
링크에 들어가셔서 다니고 계신 회사의 법인등록번호를 입력하시면 확인 가능합니다.
법인등록번호는 사업자 등록증에 나와있으며,
온라인으로 회사의 법인등록번호를 조회하려면
금융감독원 전자공시시스템 http://dart.fss.or.kr/ 에 들어가셔서 회사명 입력하고
검색한다음 회사이름 클릭하면 법인등록번호를 조회 할 수 있습니다.
(회원가입X 공인인증서X 바로조회 가능)
내가 조건에 부합하는지

(중소기업취업청년전세자금대출 대출대상확인)
– 대출신청일 현재 대출대상주택을 임차하고자 임차보증금 2억원 이하의 주택임대차계약을 체결하고 임차보증금의 5% 이상을 지불한 자
100%라고 해도 진행하려면 5%계약금은 있어야합니다.
따지고보면 최대 75~95%가능한거죠. 대출실행일(잔금지급일)에 돌려받는다곤 하지만요.
1. 대출신청일 현재 민법상 성년인 세대주 또는 예비세대주
-히익 현재 부모님이 세대주이고 나는 세대원인디요?
괜찮습니다. 저도 그런상황이였고 일단 그대로 진행한다음 대출실행일(=잔금지급일)에 이사갈 집으로 전입신고해서 등본 다시 제출하면됩니다.
2. 대출신청일 현재 세대주로서 세대주를 포함한 세대원 전원이 무주택인 자
-헤엑 현재 부모님 소유 주택이 있는디요?
괜찮습니다. 저도 부모님 소유 주택이 있었으나 대출실행일(=잔금지급일)에 이사갈 집으로 전입신고해서 등본 다시 제출하면됩니다.
3. 대출신청인과 배우자의 합산 총소득이 50백만원 이하인 자(외벌이가구 또는 단독세대주일 경우 35백만원 이하)
근로소득의 경우, 1개월이상 재직하여 온전한 한 달치 이상의 소득이 존재해야 함
->부부합산 연봉5000…알바를 해도 넘겠네요 한명은 일하지 말란소리군욥ㅠ
->외벌이 연봉3500이하인 자…오리 연봉 공개되버렸죠
네 제 작년 연봉은 3500 이하였네요. 헤헤. 잇더즌메러
->연봉의 3.5배까지 무난하게 나온다고 합니다. 다른 대출받은 이력이 있다면 조정되겠지만요.
->연봉은 상여금을 모두 포함한 금액이라고 합니다! 하지만 일시적인 것인데 3500을 넘었다면
일시적인 보너스였다는걸 증명할 서류를 제출하면 된다고 하네요.
4. 대출신청일 기준 중소‧중견기업에 재직중인 자 또는 중소기업진흥공단, 신용보증기금 및 기술보증기금의 보증 또는 창업자금 지원을 받은 자 중 만 34세(병역법에 따라 현역으로 병역 의무를 마친 경우 만 39세) 이하인자
여기까지 통과 못하셨나요?
아쉽지만; 중소기업/중견기업에 다니고 조건에 해당될것 같은 친구에게 추천해주는걸로..,
여기까지 통과 하셨나요?
축하드립니다! 1.2%대출 받아서 전세로 가봐욧!@!@@

하나, 주택도시보증공사를 통한 대출
(100% 가능한 주택 조건 난이도 별이다섯개…)
-건물의 총 보증금의 합이 2억이 넘지 않아야한다.
건축물관리대장에 명시된 용도가 주택or주거용오피스텔or다가구주택
으로 똑같이 명시 되어 있어야 하고 소유주가 집주인 한명이어야 합니다.

– 보증금의 80% 최대 1억까지 대출이 가능합니다.
20%정도 여유자금이 있다면
④ 준비서류
혼자준비할 것
1.신분증
-지갑에서 쏙
2.등본
– 동사무소 or https://www.gov.kr/yearendpay_main.html 온라인발급. 공인인증서+프린터 필요)
3.초본
-최근5년 주소변동 내역 포함 필수
-동사무소 or https://www.gov.kr/yearendpay_main.html 온라인발급. 공인인증서+프린터 필요)
4.가족관계증명서
-동사무소 or https://www.gov.kr/main?a=AA020InfoCappViewApp&HighCtgCD=A01008&CappBizCD=97400000004 온라인발급. 공인인증서 + 프린터 필요
-상세로 받기
5.건강보험자격득실 확인서
-건강보험공단 직접 방문 발급.
-건강보험공단 전화로 팩스로 발급받기 1577-1000.
–http://minwon.nhis.or.kr/retrieveMinwonMain.xx 온라인발급.가입필요.공인인증서필요.프린터필요.
회사에서 준비할 것
1.사업자등록증
2.주업종코드 확인자료
홈텍스
https://www.hometax.go.kr/ui/pp/yrs_index.html
로그인 – 조회/발급 – 기타조회 – 기준단순 경비율(업종코드) – 업종코드입력 – 화면 출력
3.고용보험 피보험자격 이력내역서
https://www.ei.go.kr/ei/eih/cm/lg/lgLogList210.do
마이페이지-하단 고용보험 가입이력-업장선택-출력
4.근로소득 원천징수 영수증 or 원천징수부
-직전 1년. 1년 미만인 사람은 월급 명세서
-회사 날인필
부동산에서 준비할 것
1.등기부등본
http://www.iros.go.kr/PMainJ.jsp
-주소만 알면 온라인으로 개인이 무료로 조회,출력가능
2.임대차계약서 원본
-계약시 특약넣기
-> 전세대출이 나오지 않을경우 계약금 전액을 즉시 돌려준다.
or
전세대출이 나오지 않을 경우 보증금 1000만원당 월세 5만원으로 전환한다.
3.계약금 영수증
4.건축물관리대장(주택도시보증공사의 경우만!)
⑤ 대출가능한 주택의 조건
– 임차 전용면적 25평 이하 주택
– 등기부등본 용도상 주택O 단독주택O 주거용 오피스텔O 다가구O(다가구는 조회해봐야 안다네요)
– 근린생활시설X 불법건축물X 융자많음X
⑥ 방구하기
방구하는 방법은 오프라인과 온라인 크게 두가지가 있습니다.
오프라인이 좋지만 직장인이 시간내기가 쉽지 않으니 온라인도 자주 보세용.
발로 발품팔기(가장 아날로그하지만 가장 좋은방법)
– 원하는 동네 부동산을 많이방문하며 방을 알아보고 연락처를 준다.
– 부동산이 중소기업청년전세자금대출 경험이 있어야 좋다.
온라인 발품팔기
네이버 카페

– 피터팬의 좋은방구하기https://cafe.naver.com/kig
->제가 매물을 구한 곳입니다. 직거래로 올려놓는 집주인들이 많습니다.(계약은 부동산끼고)
저는 특이하게 집주인이아니라 계약 기간이 조금 남아있던
세입자가 빨리 나가고 싶은 마음에 매물을 올려놨고,
운좋게 제가 그 글을 바로 읽고 집을 본 뒤 집주인과 부동산에서 만나 계약했습니다.
그 세입자가 이미 버팀목 전세대출로 살고있어서 심사는 무난히 될거라 안심했지요.
– 청년 주택정보 카페https://cafe.naver.com/lhuniv9
->LH전세대출이 대출조건이 정말까다로운데 그곳에 살고있는 사람들이 주택양도 게시판에 글을 올립니다.
대부분이 이 조건에 해당되는 매물들입니다.
->LH전세대출을 많이 진행해본 부동산 업자들이 조건에 맞는 매물을 많이 올려놓습니다.

직방
-관련업계 1위 답게 매물이 가장 많습니다. 하지만 그만큼 허위매물도 많지요. 아쉬운점은 필터에 전세자금대출이 없습니다.

다방
-내가 원하는 조건으로 상세하게 체크해서 방을 찾을 수 있습니다. 전세자금대출 가능한방 체크!
어떤 경로로든 마음에 드는 방을 찾았다?
->
등기부등본을 출력해서
->
은행에 서류와 함께 들고가서 대출신청하고 등기부등본을 보여주고. 대출이 가능한 집인지, 얼마까지 나올 수 있는지.
->
대출이 안되는 집이라면 다시 발품을 팝니다.
->
대출가능하다면 다음단계로 고고우
※주의할점 :
여러분을 기다리는 방은 분명 있습니다.
조급하게 계약하지 마세요.
마음에든다고 무작정 계약했다가
대출안되는집 잘못걸리면 시간과 정신 날립니다.
⑦ 계약하기 및 확정일자 및 대출신청
조건에 맞는집을 찾았다면 부동산에서 계약서를 작성합니다.
계약금 5%를 줍니다.(5,10%)
계약서 영수증을 받습니다.
잔금지급일을 정합니다. (대출 심사기간이 있어 2주~2달 뒤로 여유있게 정합니다)
계약서엔 특약을 넣습니다
– 대출심사거절시 계약금 반환한다.
– 대출이 전부 나오지 않을경우 보증금 1000만원당 5만원 월세로 전환한다.
계약서를 들고 해당 동사무소에 가서 확정일자를 받습니다.
확정일자 받은 계약서와 서류들을 꼼꼼히 챙기고 은행에 방문합니다.
(은행도 한가한 은행일 수록 일처리가 빠릅니다. 쌓아놓고 선착순으로 처리하기에…그리고 청년전세자금대출 경험 있는 은행원에게 합시다)
대출을 신청합니다. 수많은 서류에 싸인을 합니다.
대출 심사 뒤 연락을 준다고 합니다.
집에 갑니다.
대출실행일 = 잔금지급일
⑧ 대출실행
대출실행일을 기다립니다.
은행에서 연락이 안온다는건 잘되고 있다는 것.
믿고기다립시다.
대출실행날이되고 대출문자를 받고
집주인에게 잔금을 지급한 뒤
이사갈 집에 해당되는 동사무소에 방문해서
전입신고를 합니다.
그리고
혼자 세대주가 되어있는 등본을
새로 발급받아 은행에 제출합니다.
(원래 혼자 세대주로 있었다면 안내도대용)
대출실행일에 보증비용이 통장에서 빠져나갑니다.
(이 비용은 대출 확정시 은행원이 알려줍니다)
미리 대출통장에 어느정도 넣어놔야 일이 빨리 처리됩니다.
(1억에 30~35만원정도? 2년에 한번 빠져나갑니다(두번이였나..?)
td-agent.conf 문법
이 설정 파일을 수정하여 사용자 정의하기 전에 몇가지 문법을 확인해 보자.
설정 파일에서 쓰이는 지시자(Directives) 목록은 다음과 같다.
– source : 입력 형태 결정.
– match : 출력 목적지 결정
– filter : 이벤트 처리 파이프라인 결정
– system : 시스템 광역 설정
– label : 내부 라우팅을 위한 출력 및 필터를 그룹화
– @include : 다른 설정 파일 삽입
1. source
input 플러그인을 매개변수로 하는 지시자로 어떤 방식으로 이벤트를 입력받을 것인지 설정한다.
Fluentd 의 표준 input 플러그인에는 http 와 forward 가 있다.
http 플러그인은 fluentd 를 HTTP 엔드포인트로 바꿔 HTTP 메시지를 전달 받는다.
forward 플러그인은 fluentd 를 TCP 엔드포인트로 바꿔 TCP 패킷을 전달 받는다.
원하는 만큼 source 지시자를 추가하여 동시에 여러개의 이벤트를 받아들일 수 있다.
각 source 지시자에 사용할 input 플러그인을 tyep 파라미터(@type) 에 설정한다.
사이트에서 더 많은 input plugin 리스트를 확인할 수 있다. (http://docs.fluentd.org/v0.12/articles/input-plugin-overview)
|
# Receive events from 24224/tcp
# This is used by log forwarding and the fluent-cat command
<source>
@type forward
port 24224
</source>
# http://this.host:9880/myapp.access?json={“event”:”data”}
<source>
@type http
port 9880
</source>
|
cs |
source 는 Fluentd 의 라우팅 엔진에 이벤트를 전송한다. 이벤트는 tag, time, record 의 세 엔티티로 구성된다.
– tag 는 마침표 ‘.’ (예: myapp.access) 로 구분된 문자열이며 Fluentd 내부 라우팅 엔진의 지침으로 사용된다.
– time 필드는 input 플러그인으로 부터 지정되며 Unix 시간 형식이어야 한다.
– record 는 JSON 객체이다.
tag 는 모든 문자를 허용하지만, output 플러그인에서 다른 컨텍스트로 전달되어 사용(예: table / database / key name 등) 되기 때문에 되도록 소문자, 숫자, 밑줄 정도만 사용하는 것이 좋다. (정규식: ^[a-z0-9_]+$)
위의 예에서 HTTP input 플러그인으로 이벤트를 전송하는 예제이다.
|
# generated by http://this.host:9880/myapp.access?json={“event”:”data”}
tag: myapp.access
time: (current time)
record: {“event”:“data”}
|
cs |
2. match
match 지시자은 source 지시자로부터 전달받은 이벤트 중 일치하는 tag 가 있는 이벤트만을 찾아 처리한다.
주로 다른 시스템에 이벤트를 출력하는 등의 동작을 하여 output 플러그인이라고 한다.
Fluentd 의 표준 output 플러그인은 file 과 forward 가 있다.
file 은 다른 파일에 출력을 기록할 때, forward 는 다른 서버로 출력을 보낼 때 사용한다.
|
# Receive events from 24224/tcp
# This is used by log forwarding and the fluent-cat command
<source>
@type forward
port 24224
</source>
# http://this.host:9880/myapp.access?json={“event”:”data”}
<source>
@type http
port 9880
</source>
# Match events tagged with “myapp.access” and
# store them to /var/log/fluent/access.%Y-%m-%d
# Of course, you can control how you partition your data
# with the time_slice_format option.
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
|
cs |
각 match 지시자은 tag 와 매칭할 패턴 및 사용할 output 플러그인을 지정하는 type 파라미터(@type) 를 포함해야 한다.
패턴과 일치하는 tag 의 이벤트만 output 목적지로 전송된다. (위의 예에서는 “myapp.access” 태그가 있는 이벤트만 일치).
match 패턴
– * 는 tag 의 마침표(.)로 구분된 한 파트와 매칭 : a.* 는 a.b 와 일치, a 나 a.b.c 와 불일치)
– ** 는 tag 의 마침표(.)로 구분된 모든 파트와 매칭 : a.** 는 a, a.b, a.b.c 와 일치
– {X,Y,Z} 는 X tag, Y tag, Z tag 등이 매칭. 여러 tag 리스트를 콤마로 구분해 지정할 수 있으며 *,** 도 사용 가능하다. : a.{b,c.**} 는 a.b 나 a.c.** 와 일치
– 하나의 match 지시자안에 여러개의 패턴을 공백으로 구분할 수도 있다.
match 순서
match 지시자도 여러 개를 사용할 수 있으며 상단에 쓰여진 순서대로 일치 여부를 판단한다.
아래처럼 match 지시자가 있을 때 두번째 match 지시자(myapp.access 패턴) 는 불려질 수 없다.
|
# ** matches all tags. Bad 🙁
<match **>
@type blackhole_plugin
</match>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
|
cs |
마찬가지로 사이트에서 더 많은 output plugin 리스트를 확인할 수 있다. (http://docs.fluentd.org/v0.12/articles/output-plugin-overview)
3. filter
filter 지시자는 match 와 동일하지만, 또 다른 filter 로 전달이 가능하다. (chained pipeline)
Input -> Output 플로우가 filter 를 거치면 Input -> filter 1 -> … -> filter N -> Output 가 된다.
아래는 표준 filter 인 record_transformer 를 사용한 예이다.
|
# http://this.host:9880/myapp.access?json={“event”:”data”}
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param “#{Socket.gethostname}”
</record>
</filter>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
|
cs |
먼저 {“event”:”data”} 이벤트는 record_transformer 플러그인을 사용하여, 이벤트에 “host_param” 이라는 필드를 추가하고, 추가된 필드 {“event”:”data”,”host_param”:”webserver1″} 를 match 지시자의 file output 으로 보낸다.
<filter> 순서 역시 <match> 과 동일하게 쓰여진 순서대로 처리되므로 <match> 전에 <filter> 가 들어가야 한다.
4. system
system 지시자로 지정되는 다음 설정들은 fluentd 콘솔 명령의 옵션들과 동일하다.
log_level – 로그 표시 수준
suppress_repeated_stacktrace – true 로 설정되면 로그에 stacktrace 를 숨김 (기본값)
emit_error_log_interval – 오류 로그를 내보내는 시간 간격(초)
suppress_config_dump – 설정 파일의 내용이 로그에 표시되지 않음.
without_source – input 플러그인 없이 시작 (오래된 버퍼를 비울때 유용)
process_name – 프로세스 이름 변경
|
<system>
# equal to -qq option
log_level error
# equal to –without-source option
without_source
# …
</system>
|
cs |
5. label
label 지시자는 내부 라우팅을 위한 ouput 및 filter 를 그룹화하여, tag 처리의 복잡성을 줄여준다.
tag 접두사 없이 이벤트를 구분할 때 특히 유용하다.
label 은 내장 플러그인 파라미터이므로 매칭시킬 때는 아래 예제처럼 @ 접두사를 붙여 준다.
|
<source>
@type forward
</source>
<source>
@type tail
@label @SYSTEM
</source>
<filter access.**>
@type record_transformer
<record>
# …
</record>
</filter>
<match **>
@type elasticsearch
# …
</match>
<label @SYSTEM>
<filter var.log.middleware.**>
@type grep
# …
</filter>
<match **>
@type s3
# …
</match>
</label>
|
cs |
위 설정에서 forward 이벤트는 elasticsearch output 으로 라우트되고, in_tail 이벤트는 @SYSTEM label 의 grep filter 와 s3 ouput 으로 라우트 된다.
이처럼 label 은 <filter>, <match> 지시자등을 그룹화 할 수 있다.
@ERROR label
@ERROR label 은 플러그인의 emit_error_event API 에 의해 생성된 오류 레코드에 사용되는 내장 label 이다.
<label @ERROR> 를 설정하면 관련된 오류가 발생했을 때 이벤트가 이 label 로 라우팅 된다. (예: 버퍼가 가득 찼거나 유효하지 않은 레코드일 때)
6. @include
@include 지시자를 사용하여 별도의 설정 파일에 있는 지시자를 가져올 수 있다.
|
# Include config files in the ./config.d directory
@include config.d/*.conf
|
cs |
@include 지시자는 정규 파일, glob 패턴 및 http URL 규칙 등으로 경로를 지정할 수 있다.
|
# absolute path
@include /path/to/config.conf
# if using a relative path, the directive will use
# the dirname of this config file to expand the path
@include extra.conf
# glob match pattern
@include config.d/*.conf
# http
@include http://example.com/fluent.conf
|
cs |
glob 패턴에서 파일은 알파벳순으로 불려지므로, a.conf 와 b.conf 가 있으면 fluentd 는 a.conf 를 먼저 분석한다.
중요한 설정 파일은 안전하게 @include 로 따로 구분하라.
|
# If you have a.conf,b.conf,…,z.conf and a.conf / z.conf are important…
# This is bad
@include *.conf
# This is good
@include a.conf
@include config.d/*.conf
@include z.conf
|
cs |
빅데이터 로그 수집기, Fluentd 소개
Introducing BigData Log Aggregator, Fluentd
빅데이터를 처리하기 위해서는 각종 로그들의 수집이 필요한데, 이 때 사용하는 것이 로그 수집기(Log Aggregator)이다. 로그 수집 툴은 Scribe, Flume, Fluentd 및 logstash 등이 있는데, 이들 수집기 비교는 다음 글을 참고한다.
- Log Aggregator 비교: Log Aggregator 비교 – Scribe, Flume, Fluentd, logstash
1. Fluentd 소개
fluentd는 효율적으로 데이터를 사용하고 이해하기 위한 데이터의 수집과 소비를 통합할 수 있는 오픈 소스 데이터 수집기이다.
다음 그림은 fluentd의 아키텍쳐 그림이다. 입력과 출력을 다양화 할 수 있으며, 입/출력 부분을 사용자가 직접 코드로 작성하여 연결할 수 있는 확장성을 제공한다.
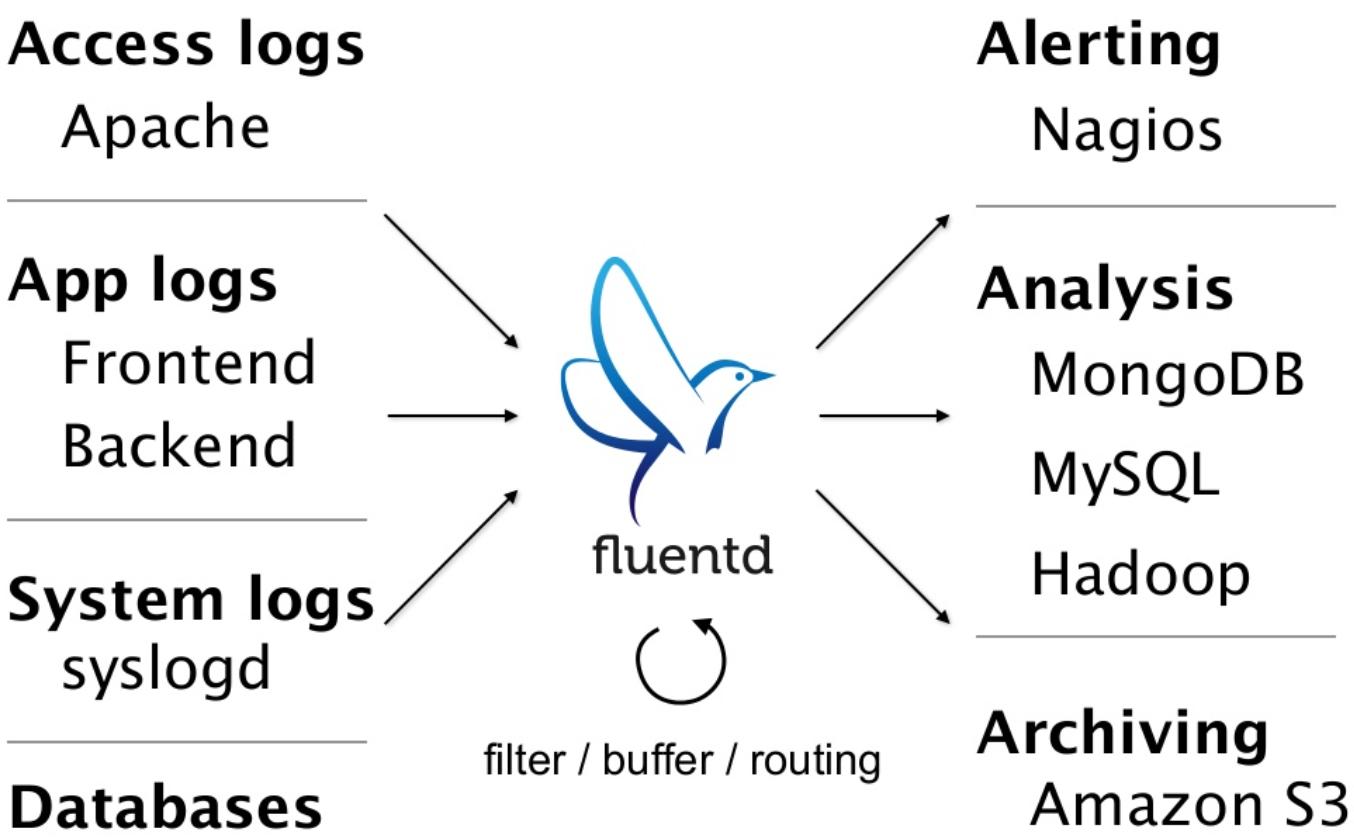
다음 그림은 다양한 형태의 입력을 받을 수 있고, 출력을 형식화 할 수 있는 fluentd의 구조를 보여준다.
Input 단계는 로그를 수집하는 모듈로 사용자화 할 수 있는 플러그인 형태이다. 따라서 다양한 로그 소스를 지원할 수 있다. File, HTTP, TCP 등 기본 플러그인을 비롯하여 확장 플러그인들을 다운로드 받거나 직접 설치할 수 있다.
Buffer는 시스템 또는 네트워크 이상 또는 부하에 따른 재처리를 위해 파일 또는 메모리를 사용하여 데이터를 유지할 수 있고, Output 역시 Input 과 동일하게 사용자화할 수 있는 플러그인 형태로 다양한 포맷으로 데이터를 변경할 수 있다.
Input 단계에서 획득한 모든 정보들이 Output 단계로 보내지는 것은 아니며, Engine에서 필터링하여 항목을 삭제하거나 추가할 수 있다. 그리고 Input 단계 또는 Output 단계는 또 다른 fluentd와 연결이 가능 가능한다.
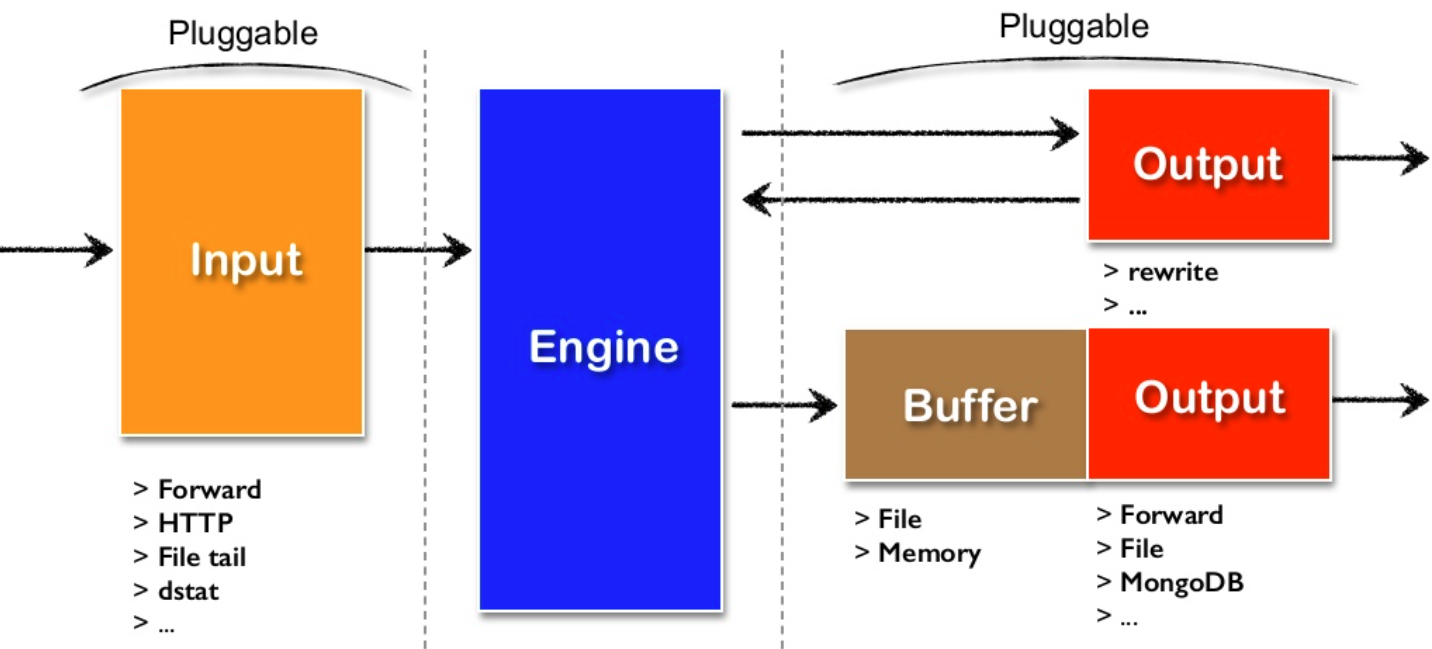
다음 그림은 문자열 형태의 웹서버 로그들을 Json 형태로 변환하여 저장하는 그림을 보여준다.

다음은 Forward 되는 fluentd 구성을 보여준다. 이 처럼 fluented는 Input과 Output 단계에서 각각 또 다른 fluentd을 둘 수 있다.
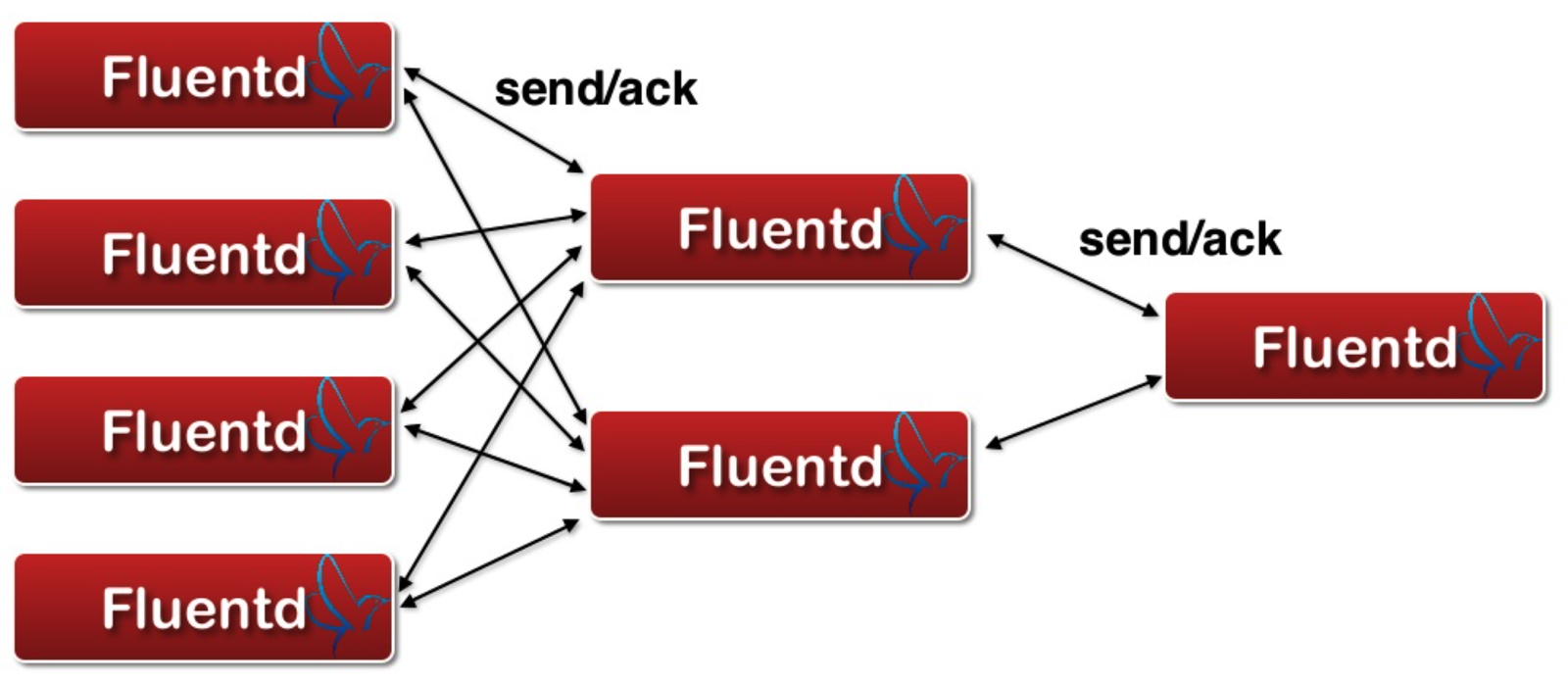
자세한 설명은 다음 슬라이드를 참고한다.
2. Fluentd 설치
설치는 다양한 방법으로 할 수 있는데, linux에서 curl을 통해 td-agent을 쉽게 설치하는 방법을 소개한다. td-agent는 fluentd 사용을 편리하게 만든 래퍼 프로그램이다.
2.1 Linux에 설치
다음은 Debian Jessie 에서 설치하는 명령이고, 다른 OS들에서 설치 명령들은 다음 주소를 참고한다. http://docs.fluentd.org/articles/install-by-deb
curl -L https://toolbelt.treasuredata.com/sh/install-debian-jessie-td-agent2.sh | sh
설치가 정상적으로 되었다면 /etc/init.d/td-agent 에 설치가 된다. 그리고 다음과 같이 정상 동작을 확인한다.
$ sudo /etc/init.d/td-agent restart [ ok ] Restarting td-agent (via systemctl): td-agent.service. $ sudo /etc/init.d/td-agent status ● td-agent.service - LSB: data collector for Treasure Data Loaded: loaded (/etc/init.d/td-agent; generated; vendor preset: enabled) Active: active (running) since Fri 2016-10-21 08:42:49 UTC; 10s ago Docs: man:systemd-sysv-generator(8) Process: 4780 ExecStop=/etc/init.d/td-agent stop (code=exited, status=0/SUCCESS) Process: 4846 ExecStart=/etc/init.d/td-agent start (code=exited, status=0/SUCCESS) Tasks: 9 (limit: 4915) Memory: 63.4M CPU: 447ms CGroup: /system.slice/td-agent.service ├─4879 /opt/td-agent/embedded/bin/ruby /usr/sbin/td-agent --log /var/log/td-agent/td-agent.log --daemon /var/run/td-agent/td-agent.pid └─4882 /opt/td-agent/embedded/bin/ruby /usr/sbin/td-agent --log /var/log/td-agent/td-agent.log --daemon /var/run/td-agent/td-agent.pid Oct 21 08:42:49 gather-twitter-data systemd[1]: Starting LSB: data collector for Treasure Data... Oct 21 08:42:49 gather-twitter-data td-agent[4846]: Starting td-agent: * td-agent Oct 21 08:42:49 gather-twitter-data systemd[1]: Started LSB: data collector for Treasure Data.
그리고 다음과 같이 td-agent을 종료할 수 있다.
$ sudo /etc/init.d/td-agent stop
데이터를 수집하기 위해서는 td-agent.conf 파일을 수정해야 한다. td-agent.conf 파일은 다음 경로에 위치한다.
/etc/td-agent/td-agent.conf3. HTTP로 샘플 로그들 수집
td-agent.conf 파일을 열어 보면 HTTP로 수집하는 입력 정보는 다음과 같이 정의되어 있다.
# HTTP input# POST http://localhost:8888/?json=# POST http://localhost:8888/td.myapp.login?json={“user”%3A”me”}# @see http://docs.fluentd.org/articles/in_http @type http port 8888
예제로 json 데이터를 HTTP로 보내보자
$ sudo /etc/init.d/td-agent restart $ curl -X POST -d 'json={"json":"message"}' http://localhost:8888/debug.test
이 데이터는 기본 설정에 의해 /var/log/td-agent/td-agent.log 에 저장이 된다. 다음과 같이 데이터를 확인해 보면 샘플 로그가 HTTP을 통해 파일에 저장된 것을 확인할 수 있다.
$ cat /var/log/td-agent/td-agent.log 2016-10-21 08:36:12 +0000 [info]: reading config file path=”/etc/td-agent/td-agent.conf”2016-10-21 08:36:12 +0000 [info]: starting fluentd-0.12.26 ….
2016-10-21 08:51:17 +0000 debug.test: {“json”:”message”}
4. Google Cloud Platform(GCP)과 연동을 위한 plugin 설치
만일 수집된 데이터들을 GCP을 통해 분석한다면, VM 인스턴스 생성 때 Cloud API 접근 권한을 가능한 ‘Full API Access’을 주는 것이 좋고, 필요에 따라서는 특정 API를 지정할 수 있다. fluentd을 사용하여 수집된 데이터를 구글의 Pub/Sub로 데이터를 전달하기 위해서는 fluentd pub/sub plugin 을 추가 설치해야 한다. plugin 이름은 ‘gluent-pugin-gcloud-pubsub’ 이며, 다음과 같이 명령을 주면 설치가 가능하다.
$ sudo td-agent-gem install fluent-plugin-gcloud-pubsub
Log Aggregator 비교 – Scribe, Flume, Fluentd, logstash
우선 log aggregator가 무엇인지 한 문장으로 설명하면, 여러 머신에서 쌓인 로그들을 한 번에 분석할 수 있도록 수집하여 주는 시스템을 말한다.
요새는 특히나 클라우드 시스템이 유행하면서 같은 일을 하는 시스템임에도 다른 머신에서 돌아가는 일이 많아지면서 필요성이 크게 증가하였다.
이번 조사로 알게 된 것들을 적어보도록 하겠다.
Scribe
우선 scribe는 Facebook에서 제작하고 사용하던 log aggregator system이다.
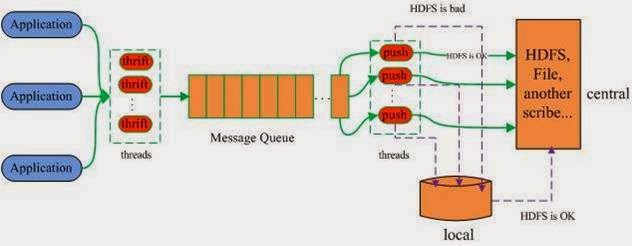 |
| scribe: http://www.cnblogs.com/brucewoo/archive/2011/12/13/2285482.html |
후에 다른 로그 수집 시스템들을 보면 알겠지만, Scribe는 다른 시스템보다 간단한 구조로 되어 있다.
Scribe는 일종의 message queue와 message queue에 쌓인 message를 DB에 저장해 주거나, DB가 실패하였으면 local에 저장하였다가 DB가 복구되었을 때 다시 DB에 저장해 주는 것만을 책임진다. 다시 말하면, message queue에 실제로 메시지를 보내는 부분은 사용자가 직접 작성하여야 한다는 것이다.
흔히들 말하는 scribe의 장점은 c++로 만든 만큼 다른 시스템들의 3~5배 정도의 성능을 보여준다는 것이다. 하지만 실제 scribe 사용자들은 무엇보다도 Facebook이 실제로 사용하였던 솔루션인 만큼 성능과 안정성에서 신뢰도가 있다는 것을 장점으로 뽑는다.
아래는 단점.
일단 가장 큰 문제는 더이상 Facebook이 Scribe를 사용하지 않는다는 것이다. Facebook은 이미 Java로 작성한 Calligraphus를 사용하기 시작했다. scribe는 open source이고 개발이 완전히 멈춘 것은 아니다. 하지만 Facebook이 중심적으로 만들던 시절에 비하면 거의 발전이 없는 상태라고 해도 될 정도이다.
앞에서 말했듯이 Scribe는 message를 보내는 부분을 완전히 새롭게 작성해야 한다. 또한, 바이너리 배포를 안하기 때문에 사용하려면 Scribe 자체도 빌드하여야 하는데 Scribe 자체가 여러 라이브러리에 의존성이 걸려있기 때문에 빌드하는 것도 쉽지 않다.
남은 장점은 성능밖에 없는 관계로 일단 다른 솔루션을 사용해보고, 그것으로 감당이 되지 않을 정도로 많은 부하가 걸리는 게 아니라면 굳이 Scribe를 사용할 이유는 없어 보인다.
Flume
다음으로 소개할 Flume은 과거 Cloudera에서 제작하여 지금은 apache의 top level project가 되었다.
Flume의 가작 큰 특징(?)은 중간에 설계가 크게 바뀌었다는 것이다.
Flume의 가작 큰 특징(?)은 중간에 설계가 크게 바뀌었다는 것이다.
 |
| Flume OG: http://archive.cloudera.com/cdh/3/flume/UserGuide/ |
 |
|
|
원래의 Flume OG는 master가 존재하여 agent나 collector를 master를 통해서 제어해야 했다. 하지만 Flume NG에서는 각각의 Agent가 독립적으로 어디로 data를 보낼지 결정할 수 있다.
Flume은 deb package로 배포하고 있기 때문에 사용하기 쉽다는 장점이 있지만, plugin을 만들기 쉬운 구조가 아니므로 주어진 조건에 맞게 사용하는 것 외에는 힘들다는 단점이 있다.
Flume은 deb package로 배포하고 있기 때문에 사용하기 쉽다는 장점이 있지만, plugin을 만들기 쉬운 구조가 아니므로 주어진 조건에 맞게 사용하는 것 외에는 힘들다는 단점이 있다.
아직은 Flume을 검색하면 Flume OG 시절의 문서와 사용 방법이 나오는 경우가 있다는 것도 단점이다.
Fluentd
Fluentd는 ruby와 c로 짜여진 log aggregator 시스템이다.
 |
| fluentd: http://blog.treasure-data.com/post/13047440992/fluentd-the-missing-log-collector-software |
기본적인 구조는 Flume NG와 비슷한 구조로 되어 있다. Flume의 Source, Channel, Sink가 각각 Input, Buffer, Output이 되었다고 보면 된다.
Fluentd의 가장 큰 특징이자 장점은 각 파트별로 plugin을 만들기 쉽다는 것이다. 직접 plugin을 만들지 않더라도, ruby로 짜여 있으며 plugin을 gem으로 배포하기 때문에 plugin을 쉽게 붙일 수 있다는 것도 큰 장점이다.
Fluentd의 가장 큰 특징이자 장점은 각 파트별로 plugin을 만들기 쉽다는 것이다. 직접 plugin을 만들지 않더라도, ruby로 짜여 있으며 plugin을 gem으로 배포하기 때문에 plugin을 쉽게 붙일 수 있다는 것도 큰 장점이다.
그러면서도 성능이 필요한 부분은 c로 작성하여 ruby로 wrapping을 하였기 때문에 성능이 크게 떨어지지도 않는다.
물론 Fluentd도 단점이 있다.
중요한 부분은 c로 짜여 있다고 해도 대부분의 부분이 scribe보다는 느리다.
대부분이 ruby로 짜여 만큼 ruby의 고질적인 문제인 memory fragmentation을 피할 수 없다.
로그에 시간을 반드시 남기게 되어 있기 때문에 agent들 사이에 시간이 맞지 않으면 log가 이상하게 쌓이기도 한다.
하지만 이런 문제들은 전부 어렵지 않게 해결할 방법이 있다.
scribe보다 느리다고 했지만, 대부분 시스템에서 사용하기에는 충분하다. 그래도 느리다면 멀티코어를 이용하는 플러그인을 사용하면 된다.
memory fragmentation은 jemalloc을 사용하면 된다.
시간이 맞지 않는 문제는 클라이언트들에서 ntpd를 돌리면 해결된다.
사용하기 쉽고, 단점들을 해결하기도 쉽기 때문에 아마 Fluentd를 사용하게 될 것 같다.
logstash
logstash는 다른 것들과는 약간 다른 관점에서 조사하다가 나온 것이다.
로그를 수집하였다고 하더라도 수집된 로그를 분석하여 보기좋게 표현할 방법이 없으면 그건 그저 information이 되지 못한 단순한 data일 뿐이다.
logstash는 elsaticsearch family의 하나가 되면서 쌓인 로그를 웹으로 보여주는데 좋은 툴인 kibana와 함께 쓸 수 있어서 손쉽게 로그를 보고 분석할 수 있는 기능을 제공해준다.하지만 fluentd도 kibana를 붙일 수 있고, logstash자체의 기능이 fleuntd보다 못하기 때문에 굳이 logstash를 쓸 일은 없어 보인다.
로그를 수집하였다고 하더라도 수집된 로그를 분석하여 보기좋게 표현할 방법이 없으면 그건 그저 information이 되지 못한 단순한 data일 뿐이다.
logstash는 elsaticsearch family의 하나가 되면서 쌓인 로그를 웹으로 보여주는데 좋은 툴인 kibana와 함께 쓸 수 있어서 손쉽게 로그를 보고 분석할 수 있는 기능을 제공해준다.하지만 fluentd도 kibana를 붙일 수 있고, logstash자체의 기능이 fleuntd보다 못하기 때문에 굳이 logstash를 쓸 일은 없어 보인다.